49_[db]pl sql 레코드와 컬렉션
PL/SQL - 레코드와 컬렉션
1. 레코드
- 자료형이 각기 다른 데이터를 하나의 변수에 저장할 때 사용
[USAGE]
--타입 선언
TYPE 레코드이름 IS RECORD(
변수이름 자료형 NOT NULL:= 값,
변수이름 자료형 NOT NULL:=DEFAULT 값 또는 값이 도출되는 여러 표현식
);
--레코드 타입을 선언 후 사용(일반 변수처럼)
변수이름 레코드이름;
- 참고로 NOT NULL은 생략할 수 있다!
- 그리고 레코드는 참조형 변수도 사용가능하다!

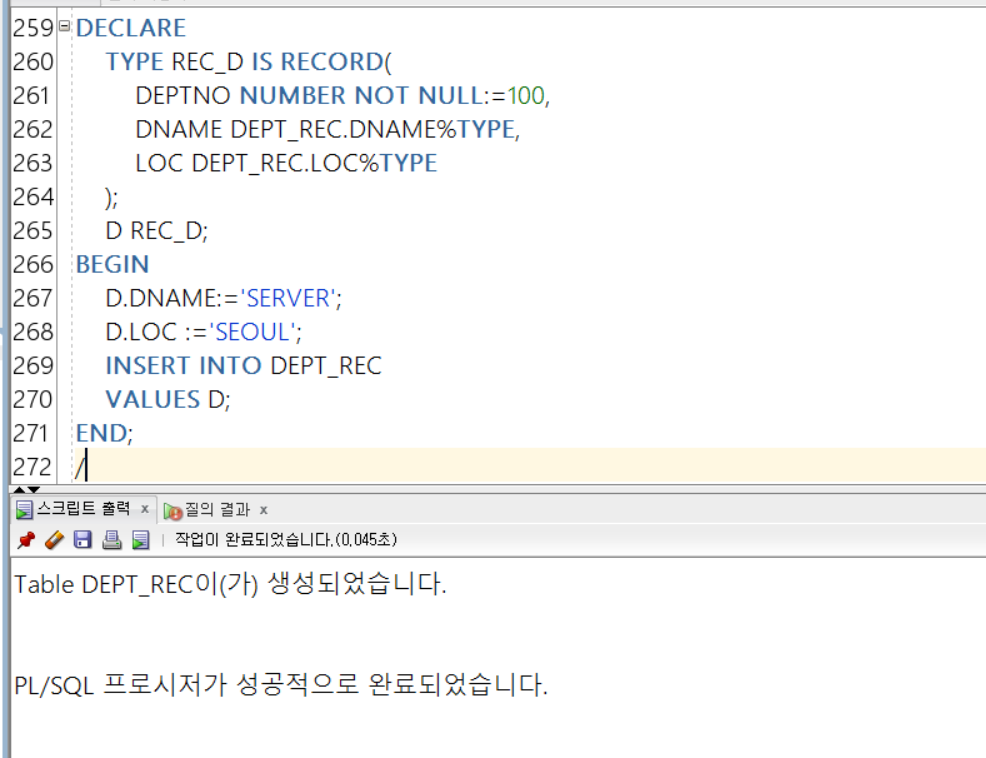
🌺 레코드를 이용한 INSERT 작업
- 레코드를 이용하게 되면, 참조형 변수에 값을 저장해두었다가(구조를 참조했던 변수에 값을 넣은 것) VALUES에 레코드를 넣어주면 기존에 사용했던 VALUES(값,값,값)보다 효율적으로 INSERT 작업을 실행할 수 있다!

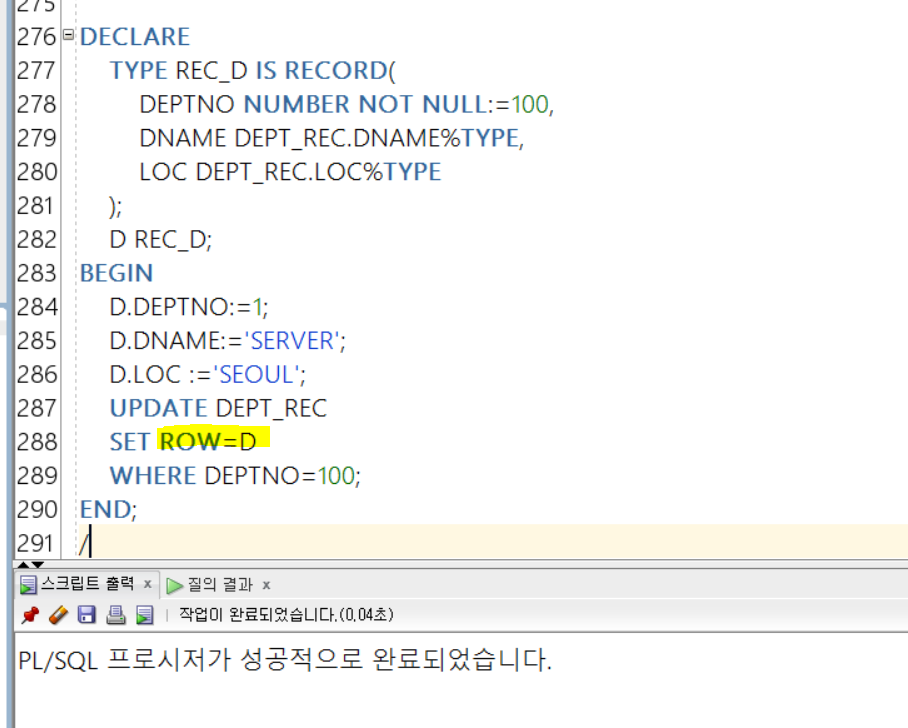
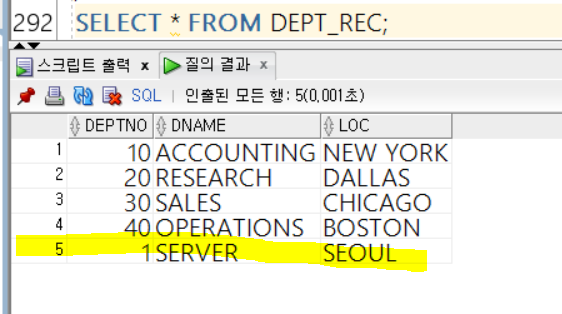
🌺 레코드를 이용한 UPDATE 작업
이번에는 UPDATE 절에서 SET 부분에
ROW=레코드
를 넣어주게 되면 보다 효율적인 UPDATE 작업을 수행할 수 있다!
🌺 중첩 레코드 Nested Record
- 레코드 내부에 또 다른 레코드가 포함된 형태
- 하나의 레코드 내부에 또 다른 레코드가 변수 사용하는 방식처럼 포함되어 있는 형태!
DECLARE
TYPE REC_D IS RECORD(
DEPTNO NUMBER NOT NULL:=100,
DNAME DEPT_REC.DNAME%TYPE,
LOC DEPT_REC.LOC%TYPE
);
TYPE REC_E IS RECORD(
EMPNO EMP.EMPNO%TYPE,
ENAME EMP.ENAME%TYPE,
RD REC_D
);
RE REC_E;
BEGIN
SELECT E.EMPNO, E.ENAME, D.DEPTNO, D.DNAME,D.LOC
INTO RE.EMPNO, RE.ENAME,RE.RD.DEPTNO,RE.RD.DNAME,RE.RD.LOC
FROM EMP E, DEPT D
WHERE E.DEPTNO=D.DEPTNO AND E.EMPNO=7788;
DBMS_OUTPUT.PUT_LINE('EMPNO: '||RE.EMPNO);
DBMS_OUTPUT.PUT_LINE('ENAME: '||RE.ENAME);
DBMS_OUTPUT.PUT_LINE('DEPTNO: '||RE.RD.DEPTNO);
DBMS_OUTPUT.PUT_LINE('LOC: '||RE.RD.LOC);
END;
/
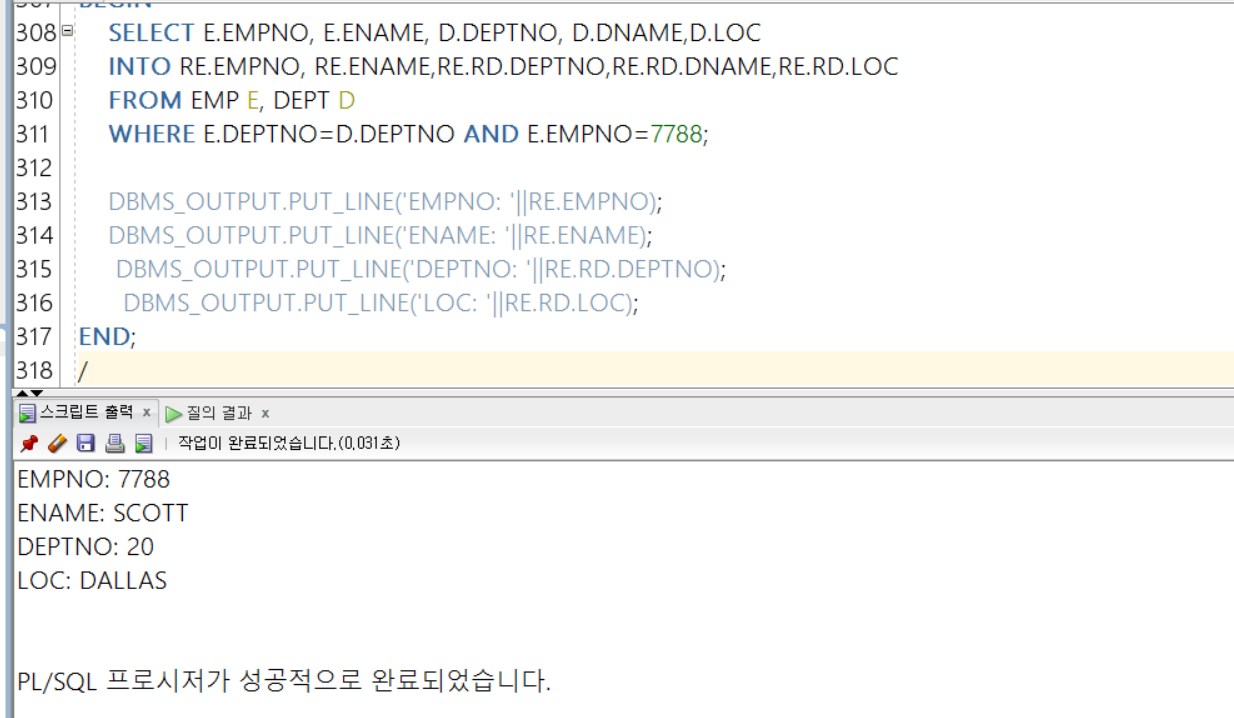
위의 예시처럼, 중첩 레코드에서 특정 테이블의 컬럼을 참조하고 있다면, INTO 키워드를 이용하여 중첩된 레코드와 그를 감싸는 레코드 모두 매치시켜줄 필요가 있다! 그리고 중첩된 레코드를 접근하기 위해서는
바깥 레코드.중첩된 레코드.변수 RE.RD.DEPTNO
로 접근해야 함을 눈여겨볼 필요가 있다!
2. 컬렉션 Collection
- 열 또는 테이블과 같은 형태로 사용 가능
- 자료형이 같은 여러 데이터를 저장하는 형태
- 종류 : 연관배열, 중첩 테이블, VARRAY(사용빈도가 높은 연관배열만을 살펴볼 것!)
2.1. 연관 배열 Associative Array(=Index by Table)
- 키[◀️ 인덱스라고도 불림)와 값으로 구성되는 컬렉션
- 중복되지 않은 유일한 키를 통해 값을 저장하고 불러오는 방식 ▶️ 자바의 HashMap 구조와 유사!
- 자료형이 TABLE인 변수작성
[USAGE]
TYPE 연관배열이름 IS TABLE OF 자료형 [NOT NULL]
INDEX BY 인덱스형;
🌹 인덱스형 : 정수(BINARY_INTEGER, PLS_INTEGER 등), 문자 자료형(VARCHAR2)
(예) 인덱스 값을 정수로 사용하는 VARCHAR2자료형 형태의 TABLE 연관 배열
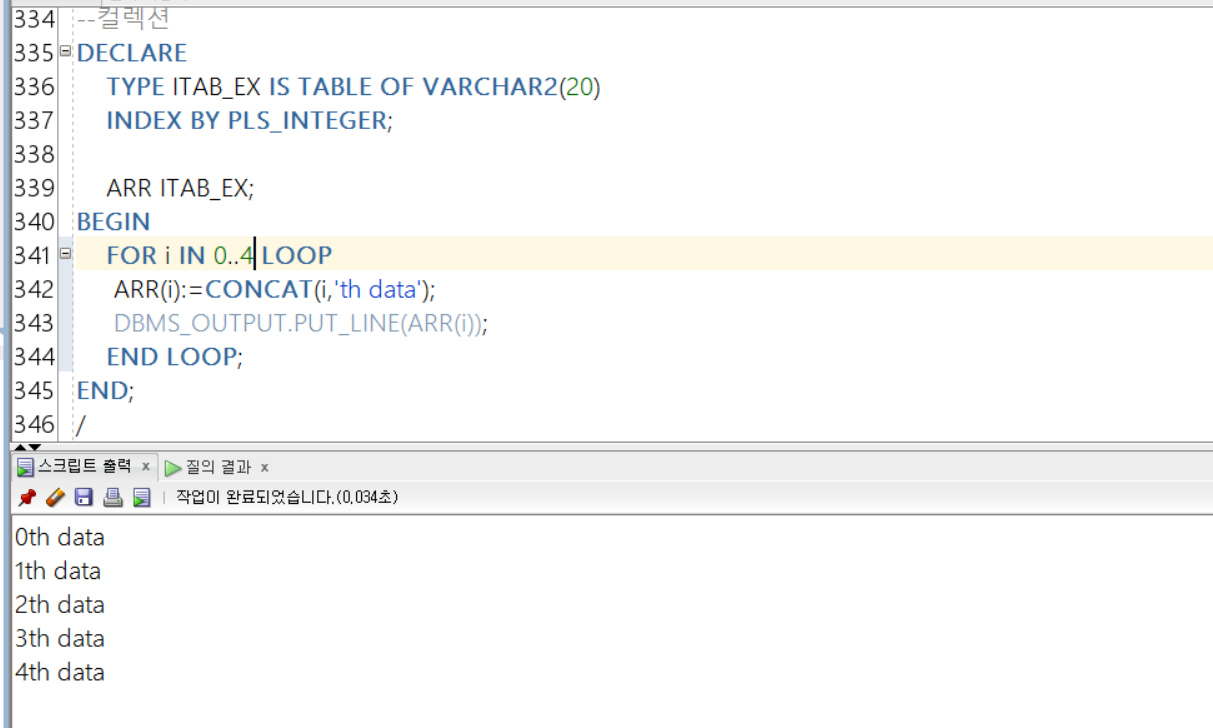
위에서 한 가지 체크해볼 필요가 있는 것은 배열에 값을 넣을 때,
배열이름(인덱스):=값 혹은 값을 도출하는 표현식
과 같은 형태로 넣어주어야 한다는 점이다! 이 부분만 추가로 알아두자
🌺 레코드를 활용한 연관배열
- 연관배열의 자료형으로 레코드 사용 가능
- 장점 - 다양한 데이터를 저장하고 사용할 수 있어서 마치 테이블처럼 데이터 사용, 저장이 가능!
- 자료형 자리에 레코드이름만 넣어주면 된다!
- 위에서는 선언부에 인덱스를 한 번 따로 명시하지 않고 FOR 루프로 처리해주었지만, 아래처럼 인덱스에 대해서 인덱스변수이름 인덱스자료형을 선언부에 적어두고 FOR루프에서 활용할 수 있다!
- 그리고 IN 다음에는
시작값..종료값
이 아니더라도
SELECT 쿼리문
이 올 수도 있다!
DECLARE
TYPE REC_DEPT IS RECORD(
DEPTNO DEPT.DEPTNO%TYPE,
DNAME DEPT.DNAME%TYPE
);
TYPE ITAB_DEPT IS TABLE OF REC_DEPT
INDEX BY PLS_INTEGER;
DEPT_ARR ITAB_DEPT;
IDX PLS_INTEGER:=0;
BEGIN
FOR i IN (SELECT * FROM DEPT) LOOP
DEPT_ARR(IDX).DEPTNO:=i.DEPTNO;
DEPT_ARR(IDX).DNAME:=i.DNAME;
DBMS_OUTPUT.PUT_LINE(DEPT_ARR(IDX).DEPTNO||' '||DEPT_ARR(IDX).DNAME);
IDX := IDX+1;
END LOOP;
END;
/
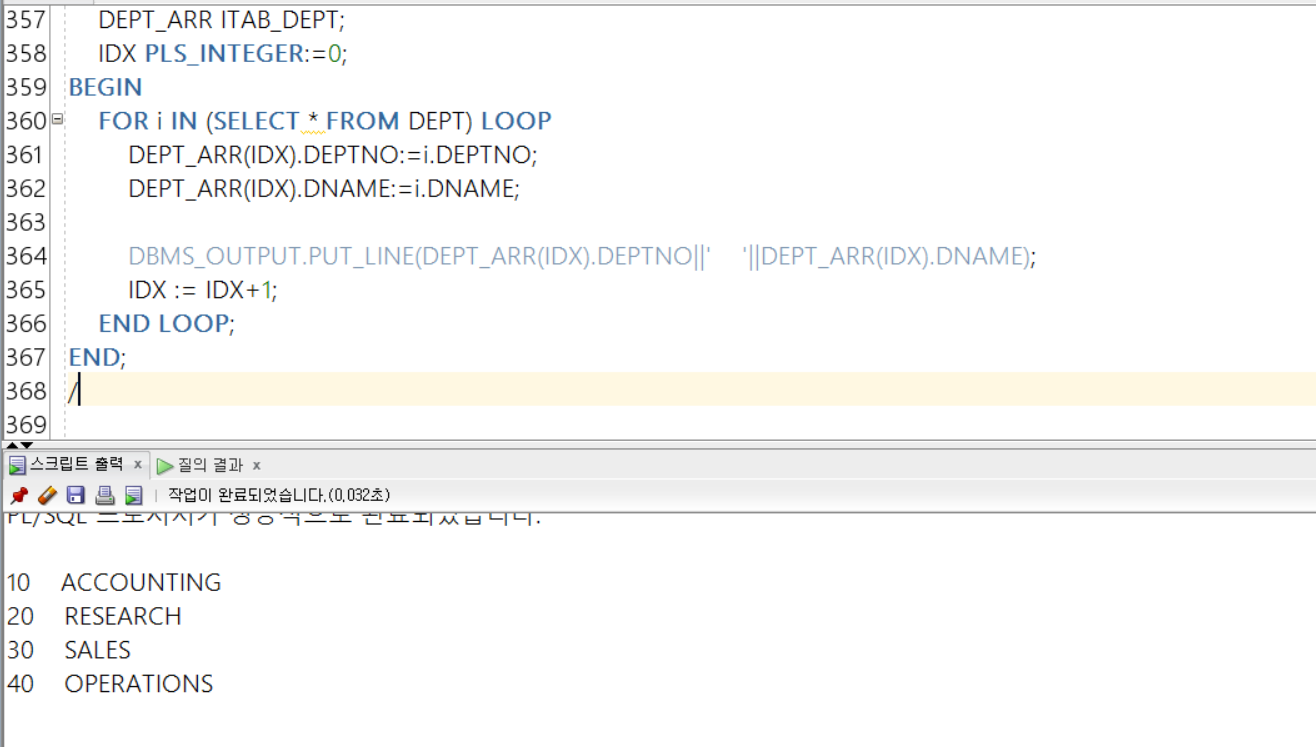
여기에서 조금 아쉬운 부분이라면, 위에서는 단지 두 개의 컬럼을 이용했지만, 전체 컬럼을 사용하고자 한다면, 위의 방식처럼 TYPE으로 참조하는 레코드를 자료형으로 삼는것 보다,
아래처럼 오히려 연관배열의 자료형을 ROWTYPE으로 특정 테이블을 참조하는 것이 보다 바람직하다!
DECLARE
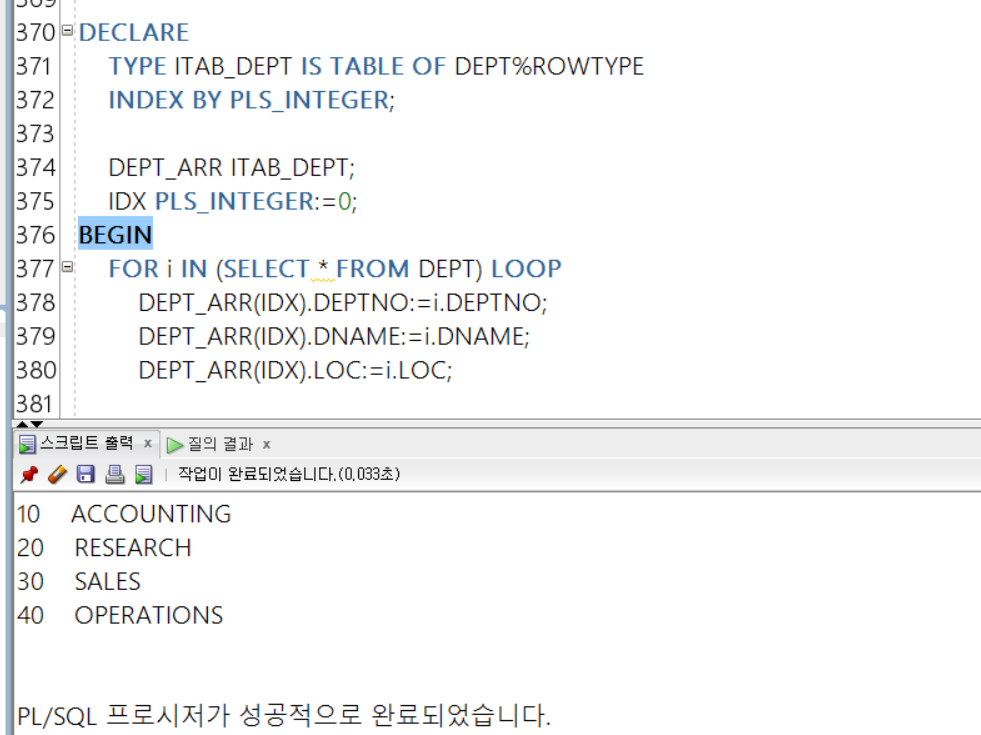
TYPE ITAB_DEPT IS TABLE OF DEPT%ROWTYPE
INDEX BY PLS_INTEGER;
DEPT_ARR ITAB_DEPT;
IDX PLS_INTEGER:=0;
BEGIN
FOR i IN (SELECT * FROM DEPT) LOOP
DEPT_ARR(IDX).DEPTNO:=i.DEPTNO;
DEPT_ARR(IDX).DNAME:=i.DNAME;
DEPT_ARR(IDX).LOC:=i.LOC;
DBMS_OUTPUT.PUT_LINE(DEPT_ARR(IDX).DEPTNO||' '||DEPT_ARR(IDX).DNAME);
IDX := IDX+1;
END LOOP;
END;
/
2.2. 컬렉션 메서드
- 컬렉션 사용상의 편의를 위한 서브 프로그램
- 다양한 정보 조회 뿐 아니라, 데이터 삭제나 컬렉션 크기 조절과 같은 조작도 가능
🌟 EXISTS(n)을 사용하는 데에 있어서, PL/SQL에서는 PUT_LINE으로 직접적으로 BOOLEAN을 출력할 수가 없다! 다만 , 우회하여 SYS 계정에 존재하는 유틸리티 sys.diutil.bool_to_int를 이용하여 BOOLEAN을 정수값으로 바꾸어 확인해볼 수는 있다!(마치 cpp의 boolalpha처럼)
아래는 해당 사항을 확인해볼 수 있는 글이다!
dbms_output cannot print boolean?
DECLARE
TYPE ITAB_ME IS TABLE OF VARCHAR2(20)
INDEX BY PLS_INTEGER;
ME_ARR ITAB_ME;
IDX PLS_INTEGER:=0;
BEGIN
FOR i IN 2..4 LOOP
IDX :=i;
ME_ARR(IDX):=CONCAT(i,'th data');
END LOOP;
DBMS_OUTPUT.PUT_LINE('ME_ARR.COUNT: '||ME_ARR.COUNT);
DBMS_OUTPUT.PUT_LINE('ME_ARR.LIMIT: '||ME_ARR.LIMIT);
DBMS_OUTPUT.PUT_LINE('ME_ARR.FIRST: '||ME_ARR.FIRST);
DBMS_OUTPUT.PUT_LINE('ME_ARR.LAST: '||ME_ARR.LAST);
DBMS_OUTPUT.PUT_LINE('ME_ARR.PRIOR(1): ' ||ME_ARR.PRIOR(1));
DBMS_OUTPUT.PUT_LINE('ME_ARR.NEXT(1): '||ME_ARR.NEXT(1));
DBMS_OUTPUT.PUT_LINE(sys.diutil.bool_to_int(ME_ARR.EXISTS(0)));
IF ME_ARR.EXISTS(0) THEN
DBMS_OUTPUT.PUT_LINE('인덱스 0에 값이 존재합니다');
ELSE
DBMS_OUTPUT.PUT_LINE('인덱스 0에 값이 존재하지 않습니다');
END IF;
END;
/
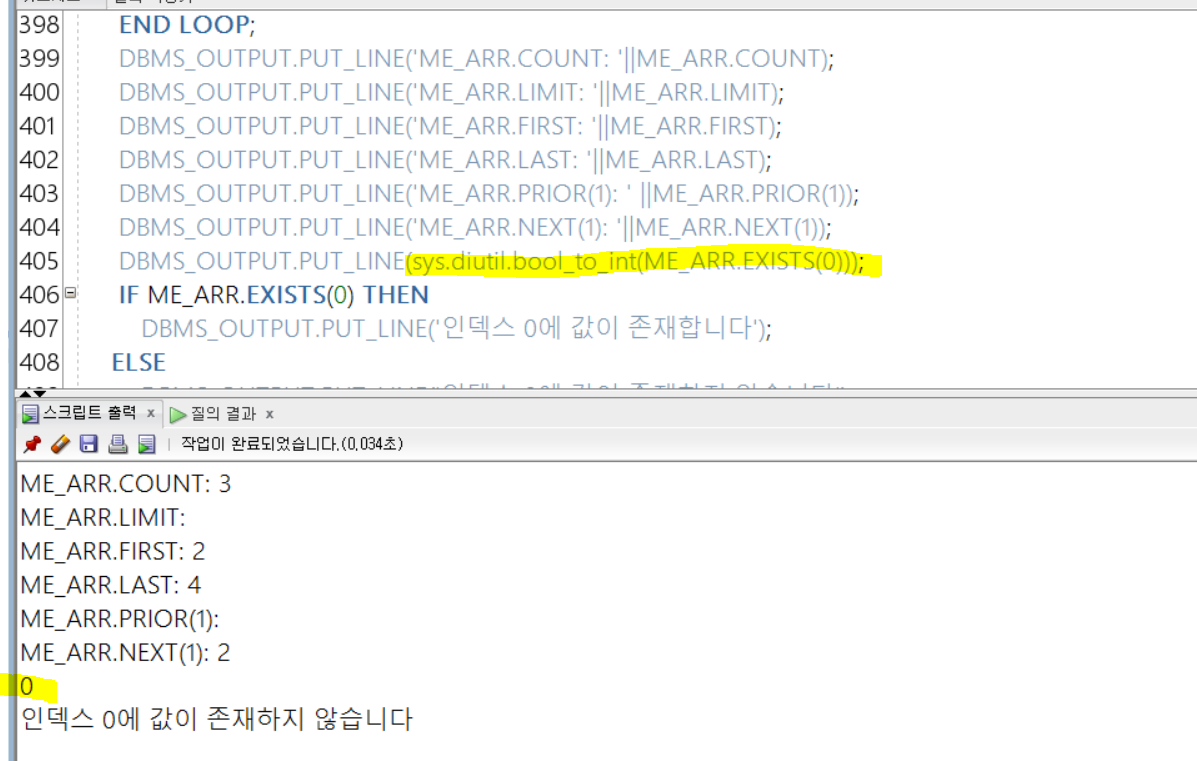
먼저 2부터 4까지의 인덱스에 값을 넣었기 때문에, 확인한 것처럼
1) 채워진 데이터 크기는 3(COUNT) 2) 처음 인덱스는 2 3) 마지막 인덱스는 4
4) 인덱스 1의 이전 요소의 인덱스는 비워져 있기 때문에 NULL, 이후의 값은 다행히 채워져 있기 때문에 인덱스 값인 2를 반환한다
그리고 한계를 정해주지 않았기 때문에
5) LIMIT은 NULL로 확인된다
더불어 sys.diutil.bool_to_int로 인덱스0에 값이 존재하는지 확인해보았는데,
존재하지 않으므로 FALSE를 반환하는데, 유틸리티에 의해서 0으로 변환된다
그리고, IF 문에 의해서 인덱스 0에 값이 존재하지 않는다는 결과문장을 확인해볼 수 있다!
마지막으로, DELETE(N,M) 부분의 개념이 다소 혼동을 일으켜서 확인하고자 정리해보자!
*보통 프로그래밍에서는 범위가 주어지면 [N,M)과 같이 적용되기 때문에 확실히 하고자 하였다!
DECLARE
TYPE ITAB_ME IS TABLE OF VARCHAR2(20)
INDEX BY PLS_INTEGER;
ME_ARR ITAB_ME;
IDX PLS_INTEGER:=0;
BEGIN
FOR i IN 2..10 LOOP
IDX :=i;
ME_ARR(IDX):=CONCAT(i,'th data');
END LOOP;
ME_ARR.DELETE(2,4);
FOR i IN 2..10 LOOP
DBMS_OUTPUT.PUT_LINE('#'||i||' : '||SYS.DIUTIL.BOOL_TO_INT(ME_ARR.EXISTS(i)));
END LOOP;
END;
/
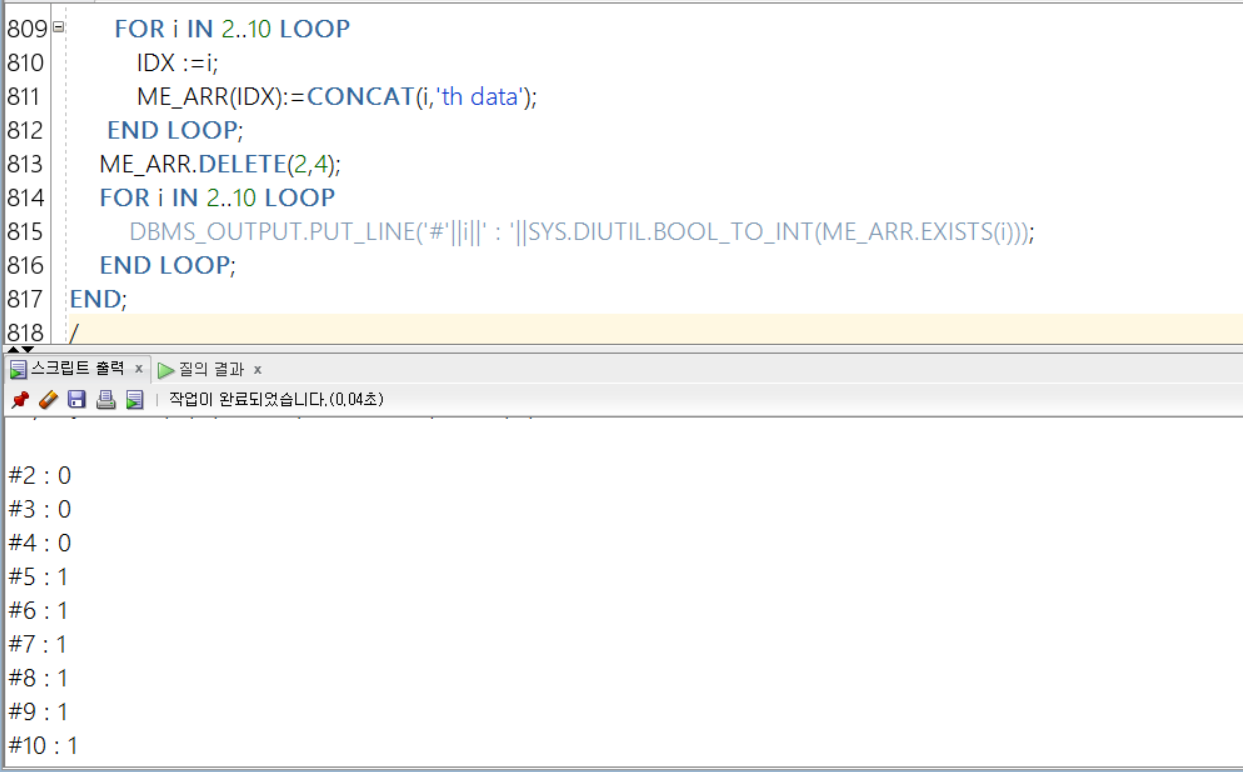
위와 같이 인덱스 2부터 10까지 값을 채워둔 후, 인덱스 2~4에 대해서 DELETE를 실행해보았다.
그 후, SYS 유틸리티와 함께 존재여부를 확인해보았다. 그 결과, [2,4]에 대해서 DELETE가 실행되었음을 확인해볼 수 있었다!
🌟 컴퓨터에서 0은 FALSE, 1은 0 이외의 모든 수! TRUTHY한 값! 였음을 잊지 말자!